

webには文字コードがいくつかあります。
代表的なものに「UTF-8」「Shift JIS」などがあります。
PHPをされる方は「UTF-8」を使ったほうがよい。とよく言われます。
なぜならば、文字化けがほとんど発生しないからです。
UTF-8は「㌔」「㌢」「㍍」といった特殊文字を含め、ほとんどの文字に対応しているため文字化けが発生しにくいという特徴があります。
それに対しShift JISはこれらの特殊文字はweb上では「文字コード」で表現されます。
いわゆる&#文字です。
&#文字は、ホームページ上では文字として表示されるため特に問題はありませんが、PHPでCSV出力をする場合には問題があります。
&#文字コードのままCSV出力されるためです。
今回は&#文字をUTF-8の通常文字に変換する方法について調べてみました。
&#文字とは
HTMLでそのままだと文字化けしたり、正しく表現されない場合に使用する文字です。
PHPだと、フォームからの入力された文字をデータベースに保存する過程で&#文字に変換するケースが多いです。
UTF-8だと&#文字に変換する必要がないためこの手間がありませんが、Shift JISベースだと&#文字に変換しないと文字化けします。
&#文字は以下のような表現になります。
<?php
$text = "✖";
echo $text;
?>

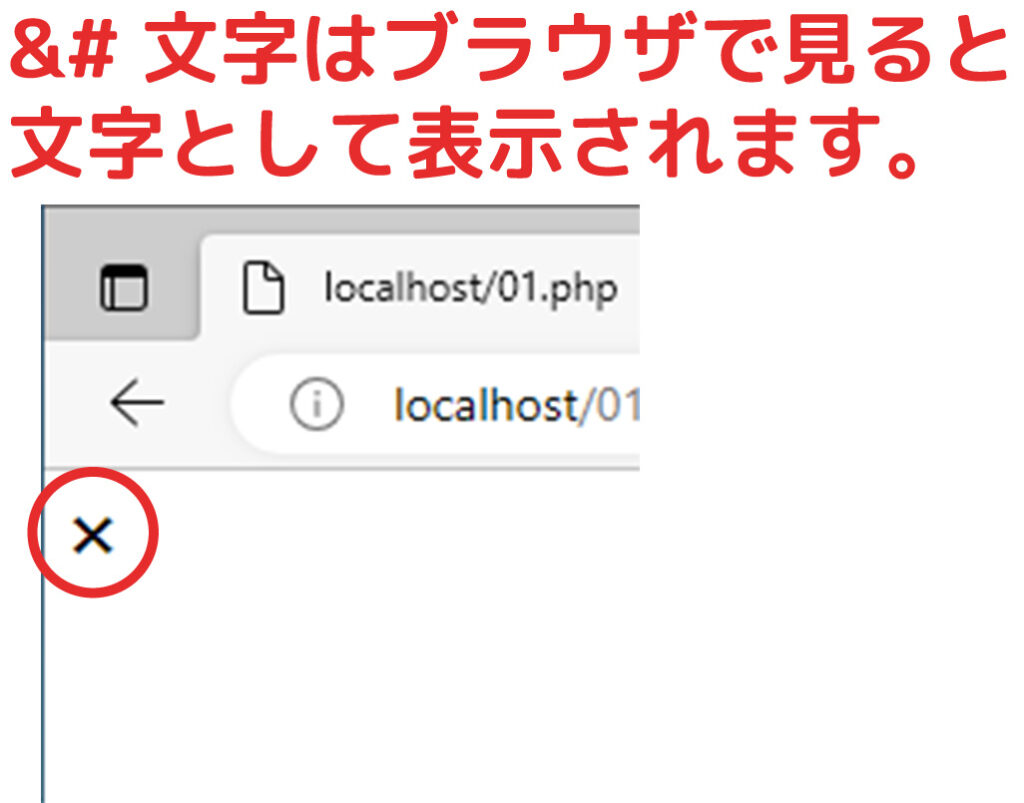
&#文字を通常文字に変換しようとして失敗した方法


Shift JISの場合、フォームから入力された文字をhtml_entity_encode()関数で&#文字に変換しています。
ならば、その逆をやればよいと思い、html_entity_decode()(復号化)すれば元に戻ると思って以下のようにやってみました。
<?php
$text = "✖";
echo html_entity_decode($text);
?>
実際にやってみたところこのようになりました。

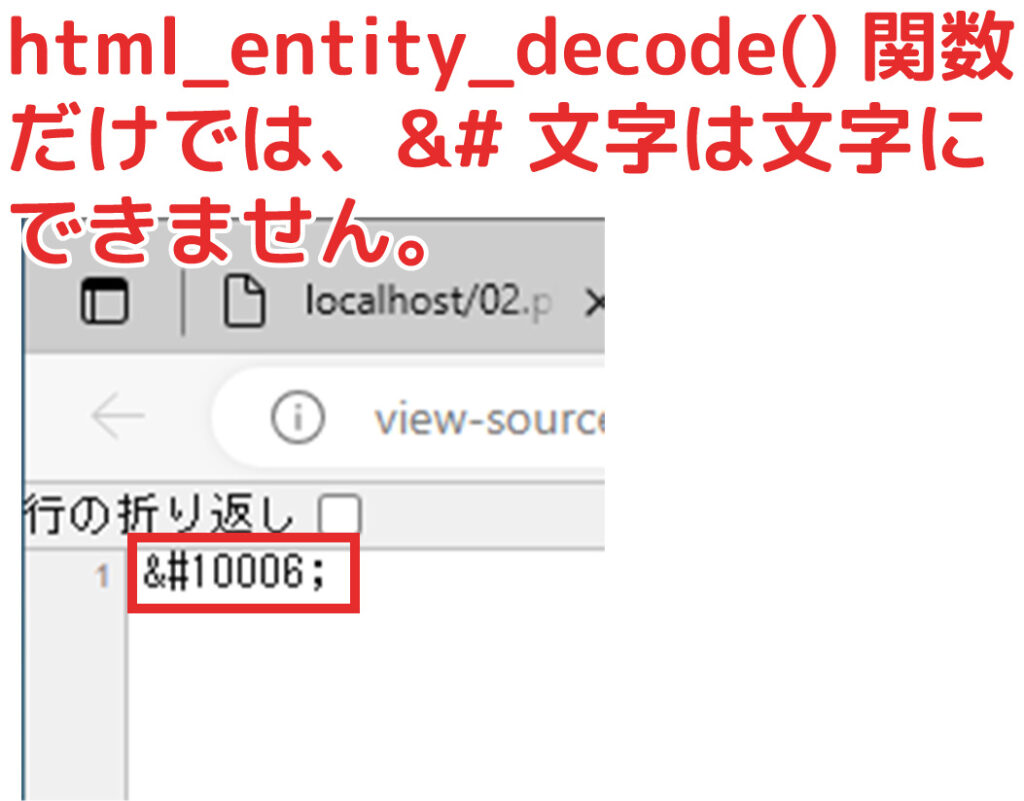
変換されませんでした。
次のようにやれば&#文字を通常文字に変換できます。


&#文字化の逆をやっても通常文字に戻らない・・。
これがこの現象のむつかしいところであり、文字コード変換の難易度を高くしている部分でもあります。
ググって調べると、次のやり方で&#文字を通常文字に変換できました。
<?php
header("Content-type:text/html;charset=UTF-8");
$text = "✖";
echo mb_convert_encoding($text, "UTF-8", "HTML-ENTITIES");
?>
&#文字を複合化するには「文字変換」で行います。
しかも、入力文字コードに「HTML-ENTITIE」を指定すれば、任意の文字コードへ変換できます。
実際にやってみたところ、以下のようになりました。

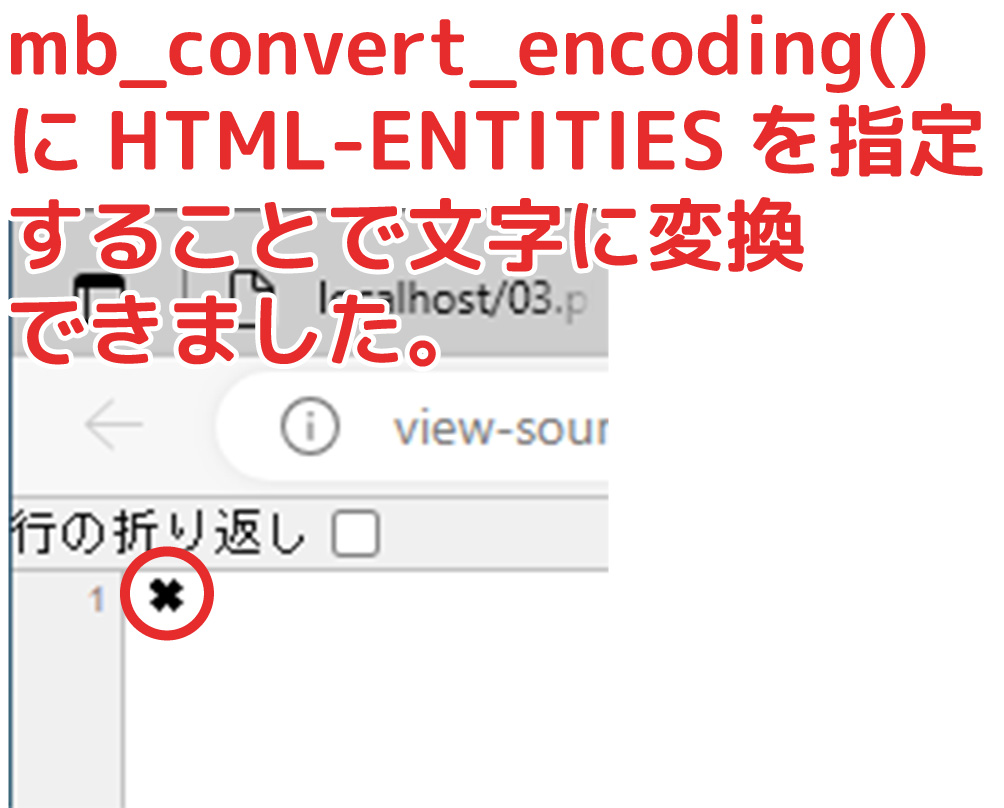
ただ、このやり方だけでは問題がありました。

&#文字が変換できたので、めでたしめでたしと思っていたら落とし穴がありました。
それは、文字と&#文字が混在しているテキストを変換すると文字化けします。
具体的には次のようなケースでは必ず文字化けします。
<?php
header("Content-type:text/html;charset=UTF-8");
$text = mb_convert_encoding("あいうえお✖かきくけこ", "UTF-8", "SJIS-win");
echo mb_convert_encoding($text, "UTF-8", "HTML-ENTITIES");
?>
通常文字と一緒に&#文字を変換してみたところ、以下のようになりました。

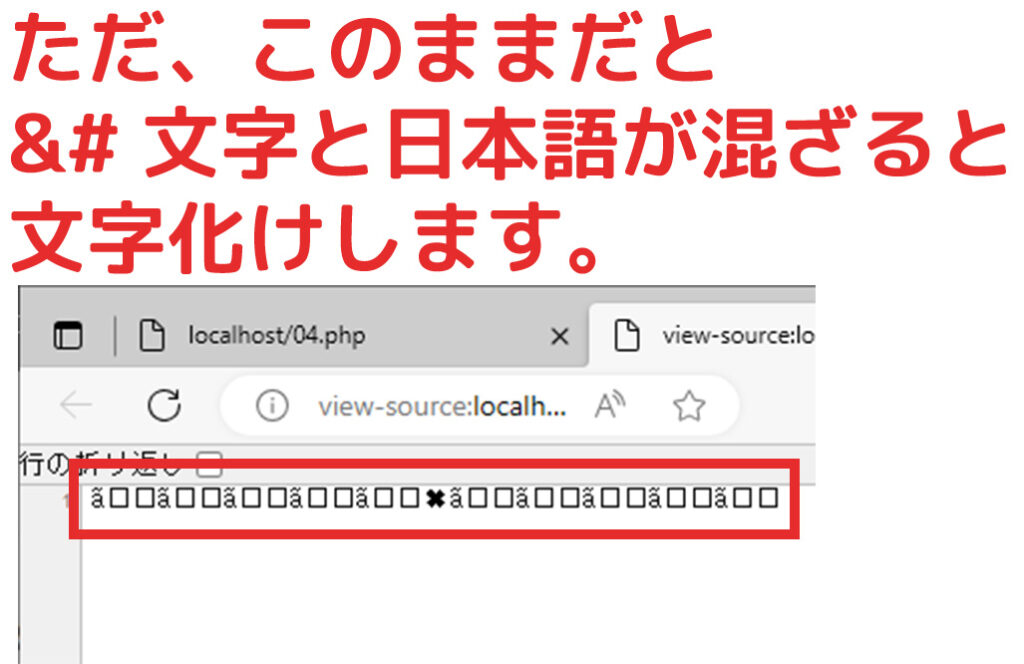
通常文字が無理やり変換されたため文字化けしました。
どうやら、通常文字を「HTML-ENTITIES」として変換してはいけないようです。
&#文字は分離して変換しないとだめなのですが、そんなことできるのでしょうか?
通常文字と&#文字混在の文章を変換する方法


通常文字を変換しないで、&#文字だけを変換する。
そんなことができるのだろうか?
と思いつつググってみると、うまいやり方がありました。
それがこちらです。
<?php
header("Content-type:text/html;charset=UTF-8");
$text = mb_convert_encoding("あいうえお✖かきくけこ", "UTF-8", "SJIS-win");
echo preg_replace_callback("/(&#[0-9]+;)/", fn($m) => mb_convert_encoding($m[1], "UTF-8", "HTML-ENTITIES"), $text);
?>
何をしているかよくわからない記述ですが、これを実行すると次のようになります。

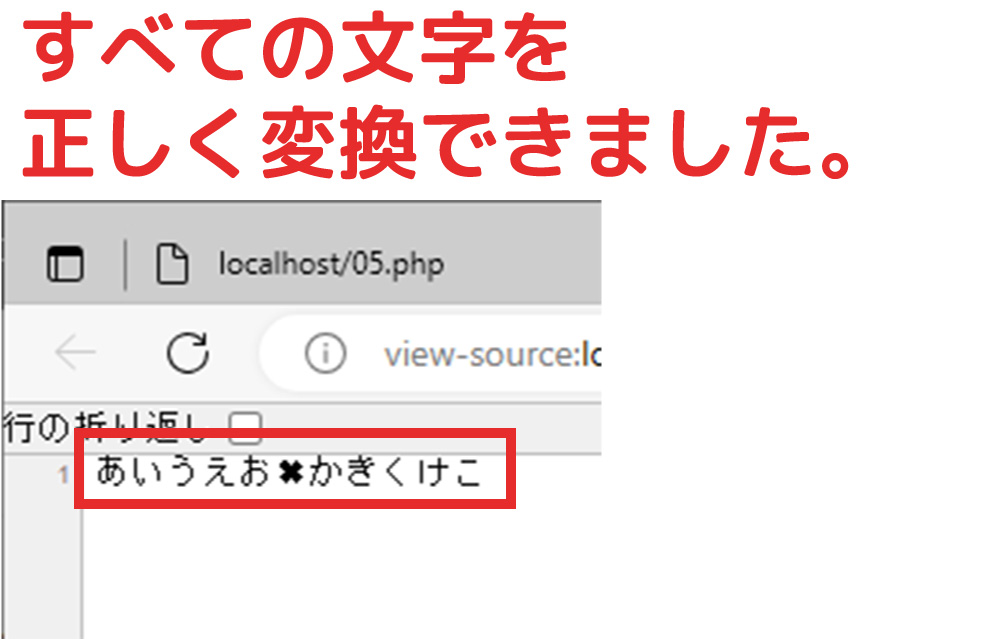
通常文字も&#文字も正しく変換できました。
やりたいことはできたのでこれでOKなのですが、ちょっと腑に落ちないことがあります。
どういう理屈で変換できているの?
ということで、なぜこの記述で変換できたのか調べてみました。
preg_replace_callback()関数でうまく変換できる理由


preg_replace_callback()関数を使って、文字変換を実行したら上手くいきました。
でもいまいち理屈がピンときません。
色々調べてその理屈がわかりました。
その内容について解説します。
(1)どういう理屈で通常文字と&#文字混在の文章を変換しているのか
最初よくわからなかったのですが、調べていると以下の理屈で変換していました。
- &#文字を抽出し、&#文字だけを変換している
通常文字と&#文字をまとめて変換すると文字化けするけれども、&#文字だけ変換すれば文字化けしません。これを実現しています。
ここで疑問がわきます。
どうやって&#文字だけを抽出しているのか?
(2) &#文字だけを抽出している方法
&#文字の抽出するために「preg_replace_callback()」関数を使用しています。
この関数は、正規表現で検索した文字列を、任意の関数に引き渡すことができる関数です。
引数は以下のようになっています。
| 第1引数 | 抽出する文字(正規表現) |
| 第2引数 | 抽出した文字を引き渡す関数 |
| 第3引数 | 検索する文字列 |
今回の事例にぴったりな関数です。
正規表現で&#文字だけを検索しmb_convert_encoding()関数へ引き渡しているのです。
(3) “/(&#[0-9]+;)/” の意味は?
正規表現で&#文字を検索するための表現になりますが、正規表現っていつも意味がよくわかりません。
調べたら次のような意味でした。
| / | /~/で囲われた部分が正規表現という意味になります。 |
| () | 正規表現のグループ化。 今回は1種類のみ検索していますが、複数パターン検索する場合/()()()/というような記述をします。 |
| &#、; | 頭が「&#」で最後の文字が「;」と一致するものという意味です。 |
| [] | []で囲われたいずれかの文字と一致するものという意味です。 0-9は0~9(0,1,2,3,4,5,6,7,8,9)という意味になります。 |
| + | 直前の文字と同じものを繰り返すという意味です。 この場合&#文字は✖、  というように数字の桁数が5桁とは限らないため、数字部分が何桁でも検索できるようにしています。 |
(4) fn($m) => ってなに?
最初この意味がよくわかりませんでしたが、調べるとアロー関数といわれる、省略表記のことでした。
今回の例は以下の表示と同じです。
fn($m)=>mb_convert_encoding($m[1], “UTF-8”, “HTML-ENTITIES”)
これは通常は以下のように記述します。
function($m) { return mb_convert_encoding($m[1], “UTF-8”, “HTML-ENTITIES”); }
PHPで関数から関数をコールすることはよくあります。
その際にfunction() と表記し、関数の中身を記述しますがそれをfn() =>とも表記できるというだけのことでした。
好きな表記方法でOKということです。
(5) mb_convert_encoding()で$m[1]を引き渡しているのはなぜ?
preg_replace_callback()関数で検索したら、結果は配列になるのは理解できますがなぜ[0]ではなく、[1]を引き渡しているのかよくわかりませんでした。
調べてみると、正規表現で検索すると[0]にはヒットした全文字が格納されます。
[1]には1個目の()でくくった文字が格納されます。
[2]には2個目の()でくくった文字が格納されます。
ちょっとピンときませんでしたが、実際に試してみると理解できました。
今回の正規表現は「/(&#[0-9]+;)/」ですが、「/お(&#[0-9]+;)か/」というような記述をすることもあり得ます。
その際に[0]には「お✖か」が入り、[1]には「✖」が格納されます。
今回は結果的には[0]、[1]どちらにも同じ値が入りますが、[1]のほうがより正しい値がGETできるため[1]をパラメータとして引き渡しています。
注意!正規表現で()を指定している場合は、抽出した値は2つ以上になりますが、()をつけなかった場合は、抽出した値は1つになります。正規表現検索に()をつけないで指定した場合は[0]を指定しましょう。
ここまで大変ならUTF-8で記述すればよいのですがShift JISを使う理由
今回ここまで苦労した理由は、システムをShift JISで組んでいたためです。
初めからUTF-8で組んでいればそもそも&#文字でCSV出力されることはありませんでした。
ではなぜShift JISで組んでいるのか?
その理由は「Microsoftとの親和性」です。
Microsoftのアプリの日本語は原則「Shift JIS」です。
Shift JISで組んでいればMicrosoftとの相性がいろいろ良くなります。
ただ、それだけではありません。
最近感じるのは、Shift JISで組むことで文字変換処理に異常に強くなりました。
いばらの道を進むことで自分の技術が向上します。
そんな理由もあります。